PIP: Positional-encoding Image Prior
Nimrod Shabtay*,
Eli Schwartz*, Raja Giryes
Electrical Engineering - Tel Aviv University
Abstract
In Deep Image Prior (DIP), a Convolutional Neural Network (CNN) is fitted to map a latent space to a degraded (e.g. noisy) image but in the process learns to reconstruct the clean image. This phenomenon is attributed to CNN's internal image-prior. We revisit the DIP framework, examining it from the perspective of a neural implicit representation. Motivated by this perspective, we replace the random or learned latent with Fourier-Features (Positional Encoding). We show that thanks to the Fourier features properties, we can replace the convolution layers with simple pixel-level MLPs. We name this scheme ``Positional Encoding Image Prior" (PIP) and exhibit that it performs very similarly to DIP on various image-reconstruction tasks with much less parameters required. Additionally, we demonstrate that PIP can be easily extended to videos, where 3D-DIP struggles and suffers from instability.
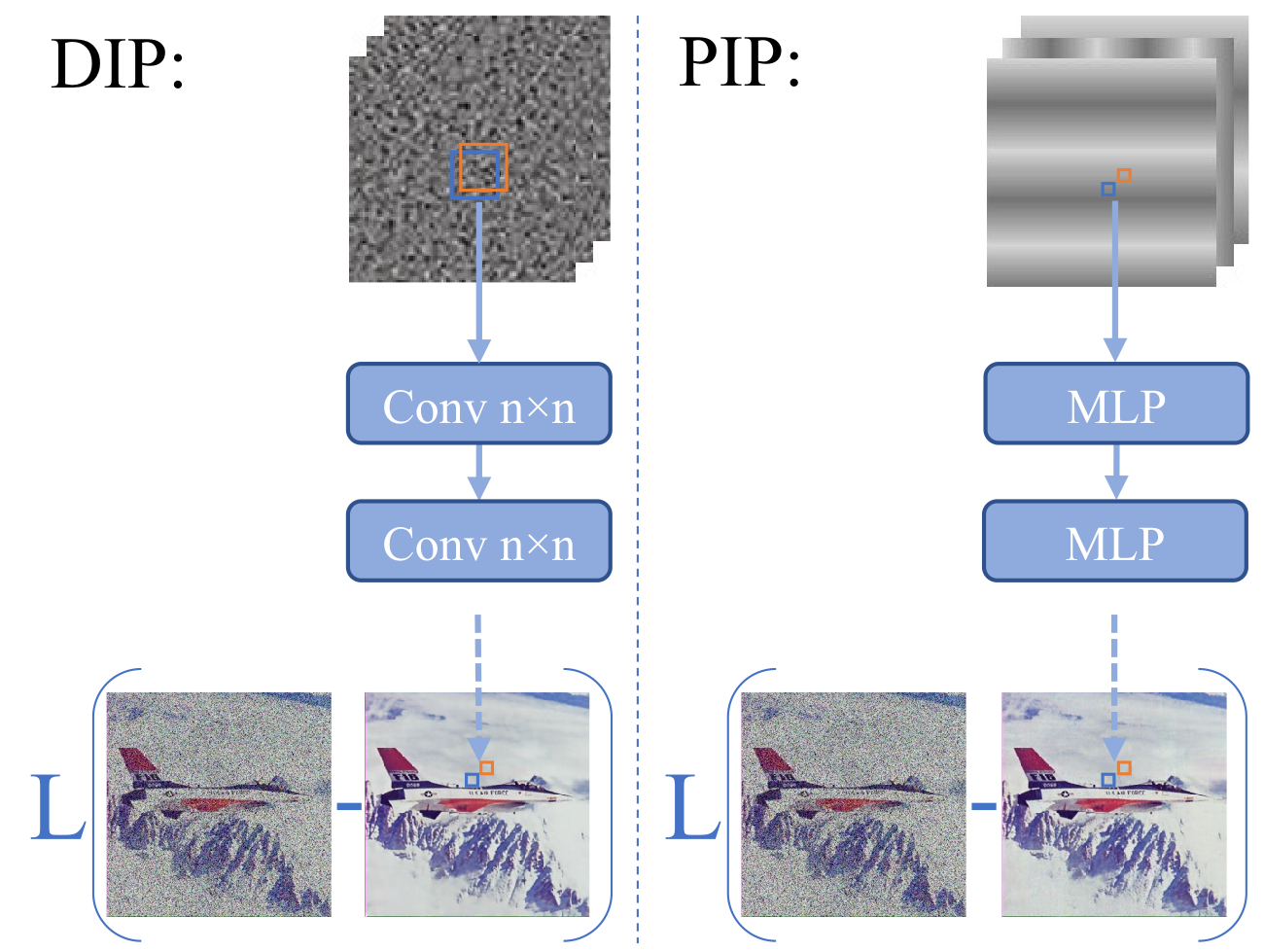
We offer a novel view of DIP as an implicit model that maps noise to RGB values (left). We suggest that the image-prior, or regularization, stems from the fact that neighboring pixels in the output image (blue and orange in the picture) are a function of almost the same noise box in the input but a bit shifted. With this implicit model perspective, we suggest that one may achieve a similar `image-prior' effect by replacing the input noise with Fourier-Features. As a result, we may use a simple pixel-level MLP that has much less parameters than the DIP CNN and still reconstruct images of the same quality. Remarkably, for video this leads to a significant improvement.















CLIP Inversion
"A moody painting of a lonely duckling"






Video Denoising

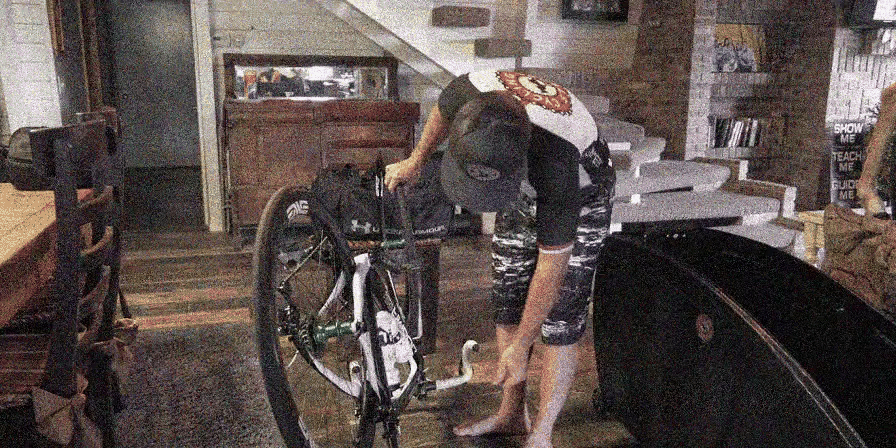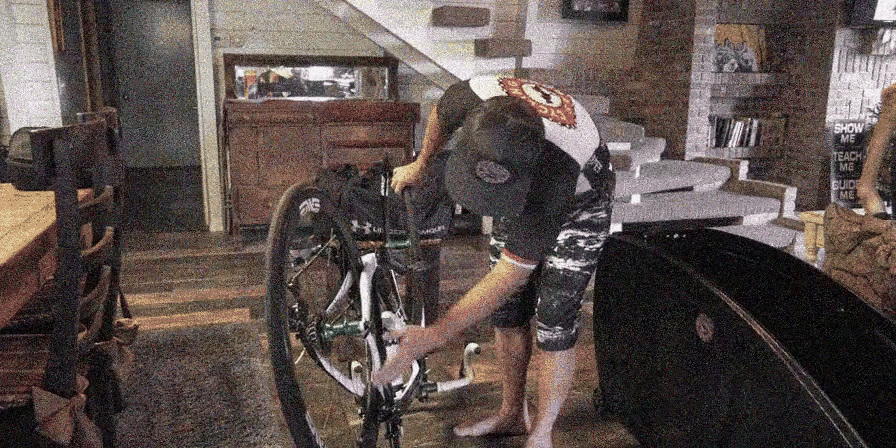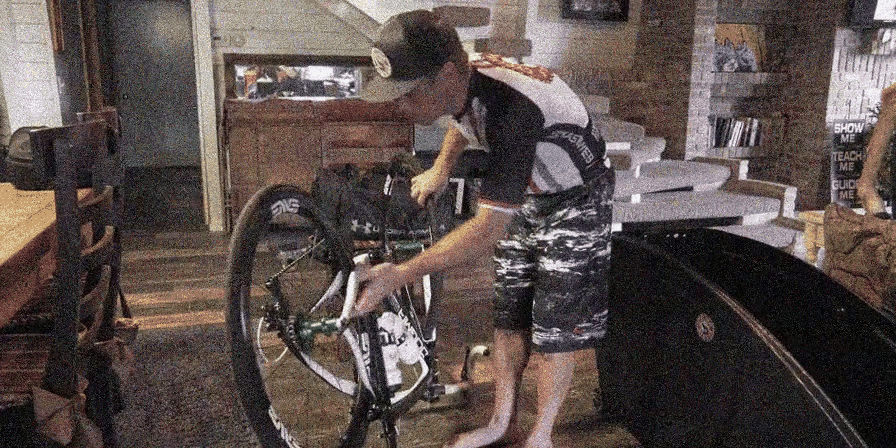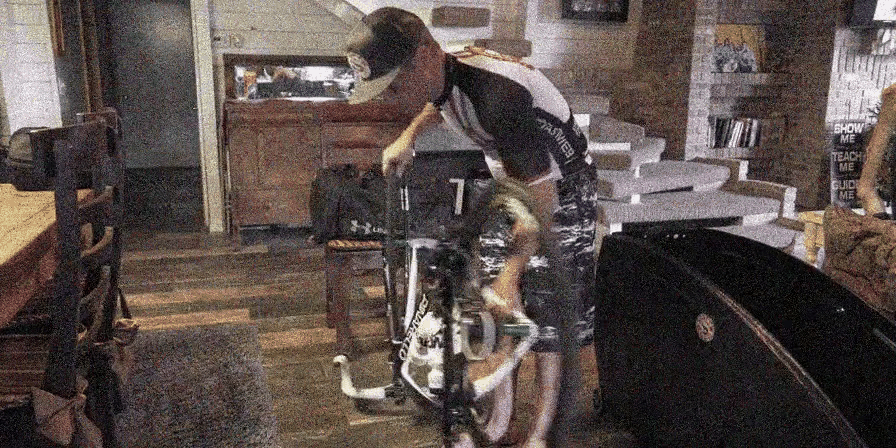


Results: Avg. PSNR(dB) / SSIM-3D
More Examples
Video SR




Results: Avg. PSNR(dB) / SSIM-3D
More Examples
BibTeX
@article{shabtay2022pip,
title={PIP: Positional-encoding Image Prior},
author={Shabtay, Nimrod and Schwartz, Eli and Giryes, Raja},
journal={arXiv preprint arXiv:2211.14298},
year={2022}
}